ClustEval Server¶
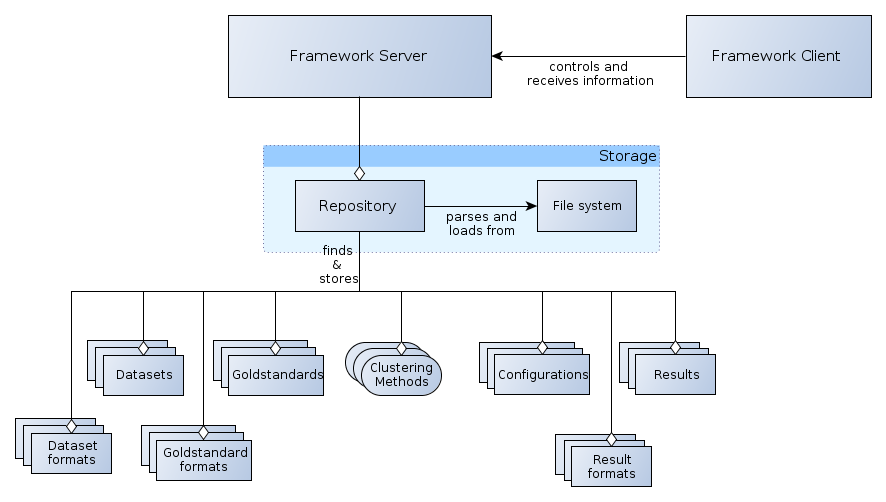
A schema of the ClustEval backend
The backend of the framework is responsible for all calculations. It consists of a server and a client component. The server takes commands from the client and does the calculations internally and in a multithreaded way. The client can query the server to get the current status of a calculation or to give commands to the server which might control current processes. Figure 2 shows the general structure of the backend and the components it contains.
In principle the core of all tasks of the backend server is, to apply clustering methods to data (data set and goldstandard) in an automatized and autonomous way, using only the configurations and inputs the user specified. The produced results have to be parsed in such a way, that the frontend can easily collect certain information and visualize them. Thus the components used by the backend that are not directly included into the framework programatically but need to be provided can be summarized as
Additional components that can be extended and might be needed in case the provided standard functionality of the framework is not sufficient for the user
- Formats - Input & Output
- Clustering Quality Measures - Is It a Good Clustering?
- Distance Measures - Converting Absolute Coordinates to Pairwise Similarities
- Parameter Optimization Methods - Finding Good Clustering Parameters
- Data Set Types - Classifying Data
- Statistics - Analyzing Data & Clusterings
- Data Set Generators - Validation On Artificial Data
- Data Preprocessors - Cleaning Data and Removing Noise
- Data Randomizer - Distorting Existing Data Sets
Repository¶
All these components have to be located in the repository of the framework (see Repository - The Central Storage of ClustEval for more details). The repository is a file system hierarchy located at a specified path and contains all components used by and available to the framework. Data sets, clustering methods or configurations outside the repository cannot be used by the framework. When these components have been made available to the backend, they can be combined almost arbitrarily. In the following we will describe the dependencies of each of these components which need to be fulfilled such that a new component of each type can be recognized and used by the framework.
More information about the above components can be found in the following sections:
CLI (Command line interface)¶
The server provides the following command line parameters:
- –absRepoPath <ABSOLUTEFOLDERPATH>
- The absolute path to the repository
- –help
- Print help and usage information
- –version
- Print the version of the server
- –port <INTEGER>
- The port this server should listen on for clients
- –logLevel <INTEGER>
- The verbosity this server should use during the logging process. 0=ALL, 1=TRACE, 2=DEBUG, 3=INFO, 4=WARN, 5=ERROR, 6=OFF
- –numberOfThreads <INTEGER>
- The maximal number of threads that should be created in parallel when executing runs.
- –checkForRunResults <BOOLEAN>
- Indicates, whether this server should check for run results in its repository.
- –noDatabase <BOOLEAN>
- Indicates, whether this server should connect to a database.
- –rServeHost <IPADDRESS|STRING>
- The address on which Rserve is listening.
- –rServePort <INTEGER>
- The port on which Rserve is listening.
ClustEval Client¶
The backend client is a small command-line tool which gives commands to the back- end server, for example to execute a certain run or terminate a run that is currently executing. It offers tab completion and communicates with the server using the Rserve package via TCP/IP.
CLI (Command line interface)¶
The client provides the following command line parameters:
- –help
- Print help and usage information
- –logLevel <INTEGER>
- The verbosity this server should use during the logging process. 0=ALL, 1=TRACE, 2=DEBUG, 3=INFO, 4=WARN, 5=ERROR, 6=OFF
- –version
- Print the version of the server
- –ip <IPADDRESS>
- The ip address of the backend server to connect to.
- –port <INTEGER>
- The port number of the backend server to connect to.
- –clientId <INTEGER>
- The client id for identification purposes of this client with the server. Each connecting client has its unique id and can only retrieve results that have been executed by the same client id.
- –performRun <RUNNAME>
- Performs a certain run (if not already running)
- –resumeRun <RESULTID>
- Resumes a certain run that was started and terminated earlier
- –terminateRun <RESULTID>
- Terminates a certain run that was started earlier.
- –getDataSets
- Queries the available datasets from the server.
- –getPrograms
- Queries the available programs from the server.
- –getRuns
- Queries the available runs from the server.
- –getRunResumes
- Queries the available run resumes from the server.
- –getRunStatus <RESULTID>
- Queries the status of a certain run
- –getOptRunStatus <RESULTID>
- Queries the optimization status of a certain run
- –getQueue
- Gets the enqueued runs and run resumes of the backend server
- –getActiveThreads
- Gets the currently active threads and the corresponding iterations which they perform
- –setThreadNumber <INTEGER>
- Sets the maximal number of parallel threads.
- –generateDataSet <GENERATORNAME>
- Generates a dataset using the generator with the given name. Usage help will be shown after this command has been executed.
- –randomizeDataConfig <RANDOMIZERNAME>
- Randomizes a dataconfig using the randomizer with the given name. Usage help will be shown after this command has been executed.
- –shutdown
- Shut down the ClustEval server.
- –waitForRuns
- The client will wait until all runs that this client started are finished.