Formats - Input & Output¶
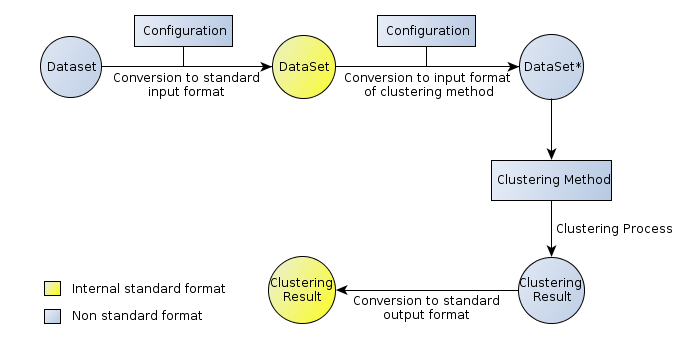
A schema of the format conversion processes in ClustEval
As already mentioned, datasets have their own formats and clustering methods can require different input and output formats. The general process how these formats link together can be visualized as seen in figure 4. A dataset of a certain format known to the framework is converted into the standard input format of the framework using the parser belonging to the format of the dataset. Then the dataset in the standard format is converted to any of the supported input formats of the clustering method using the parser belonging to the chosen supported input format of the clustering method. Now the clustering method is applied to the dataset in the supported format. A clustering result is produced in the format of the clustering method. This result is then converted to the standard output format of the framework using the parser belonging to the format of the result. The framework then has access to the clustering results of the clustering method applied to the dataset in a format it understands, such that diverse operations can be performed on the result.
If a new clustering method is added to the framework, its input and output formats need to be known to the framework. clusteval ships with a set of supported input and output formats. The input formats are
Available Formats¶
For lists of all available input and result formats see here and here respectively.
Standard Formats¶
The standard input format is the SimMatrixDataSetFormat. The standard result format is the TabSeparatedRunResultFormat.
Providing New Formats¶
If the new clustering method requires another input format not in the list, you will have to make it available to the framework by writing
- a wrapper class for this dataset format and
- a parser, which converts the standardized input format of this framework to this input format.
If the new clustering method has a so far unknown output format, you will have to provide
- a wrapper class for this output format as well as
- a parser that converts that format to the standardized output format.
When this clustering method is applied to a dataset, the resulting clustering in the new format is converted to a standardized output format using your parser, such that further analyses can be performed regardless of the used clustering method.
For more information on how the extend ClustEval by new formats see Formats.